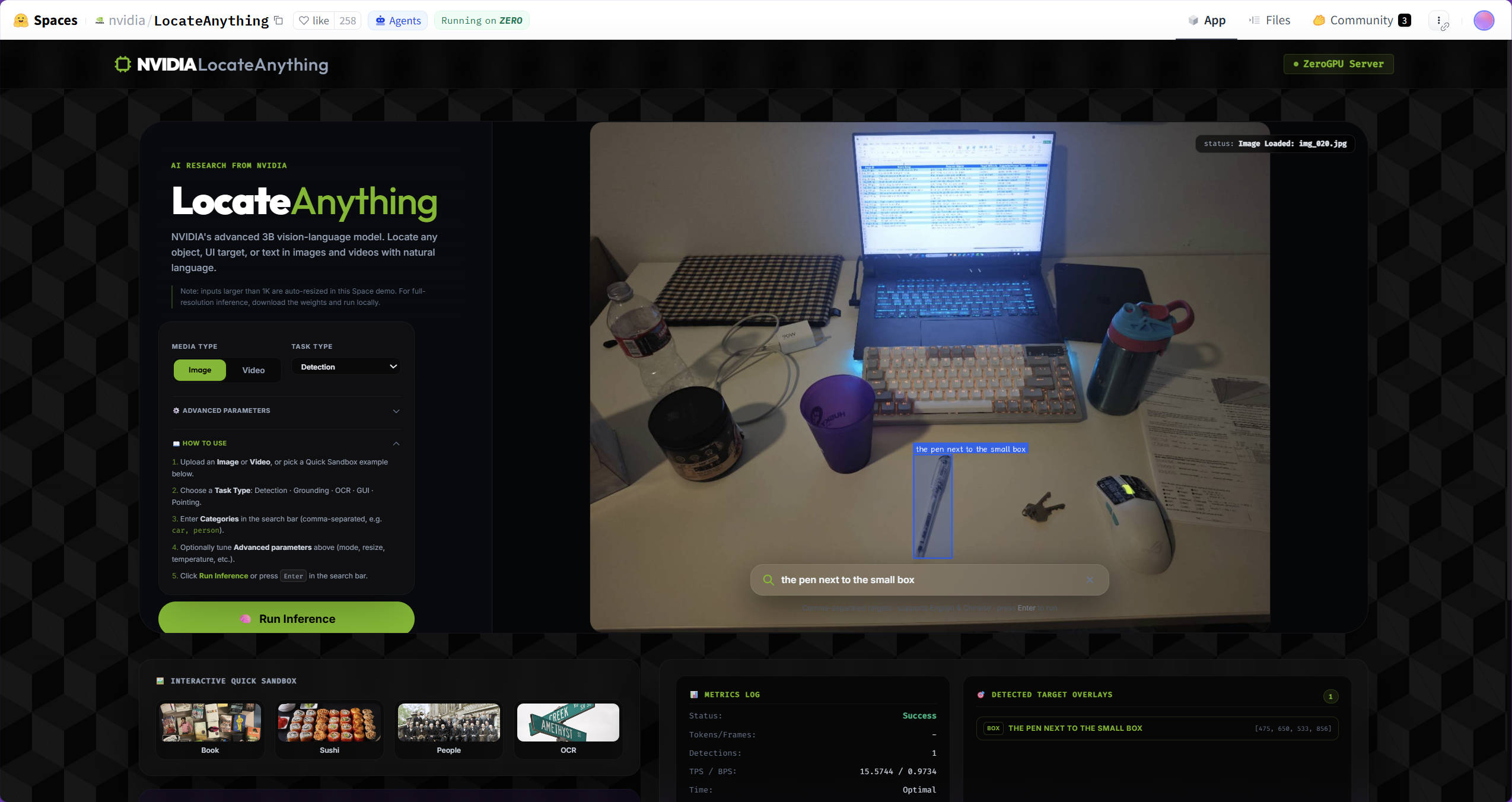
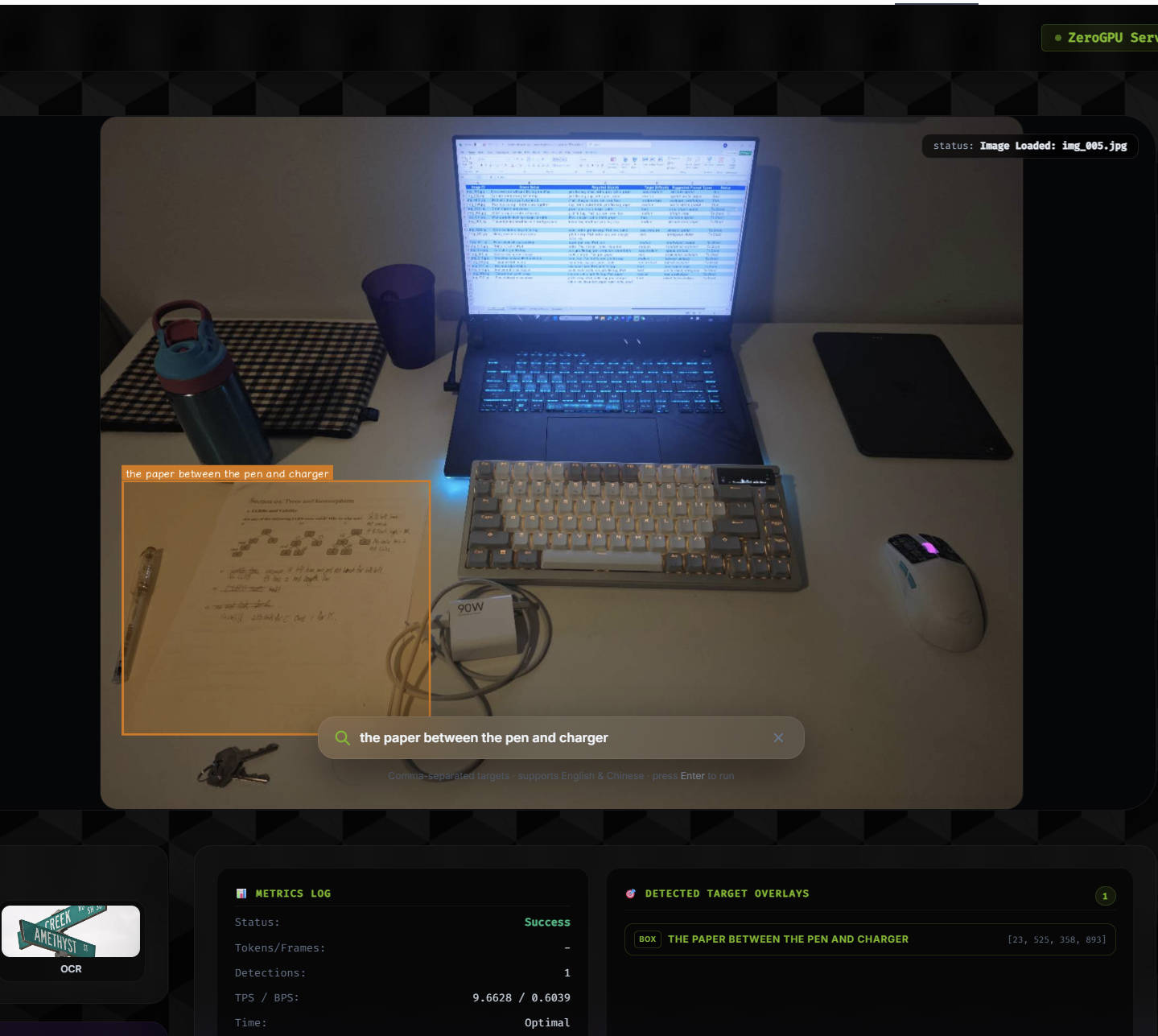
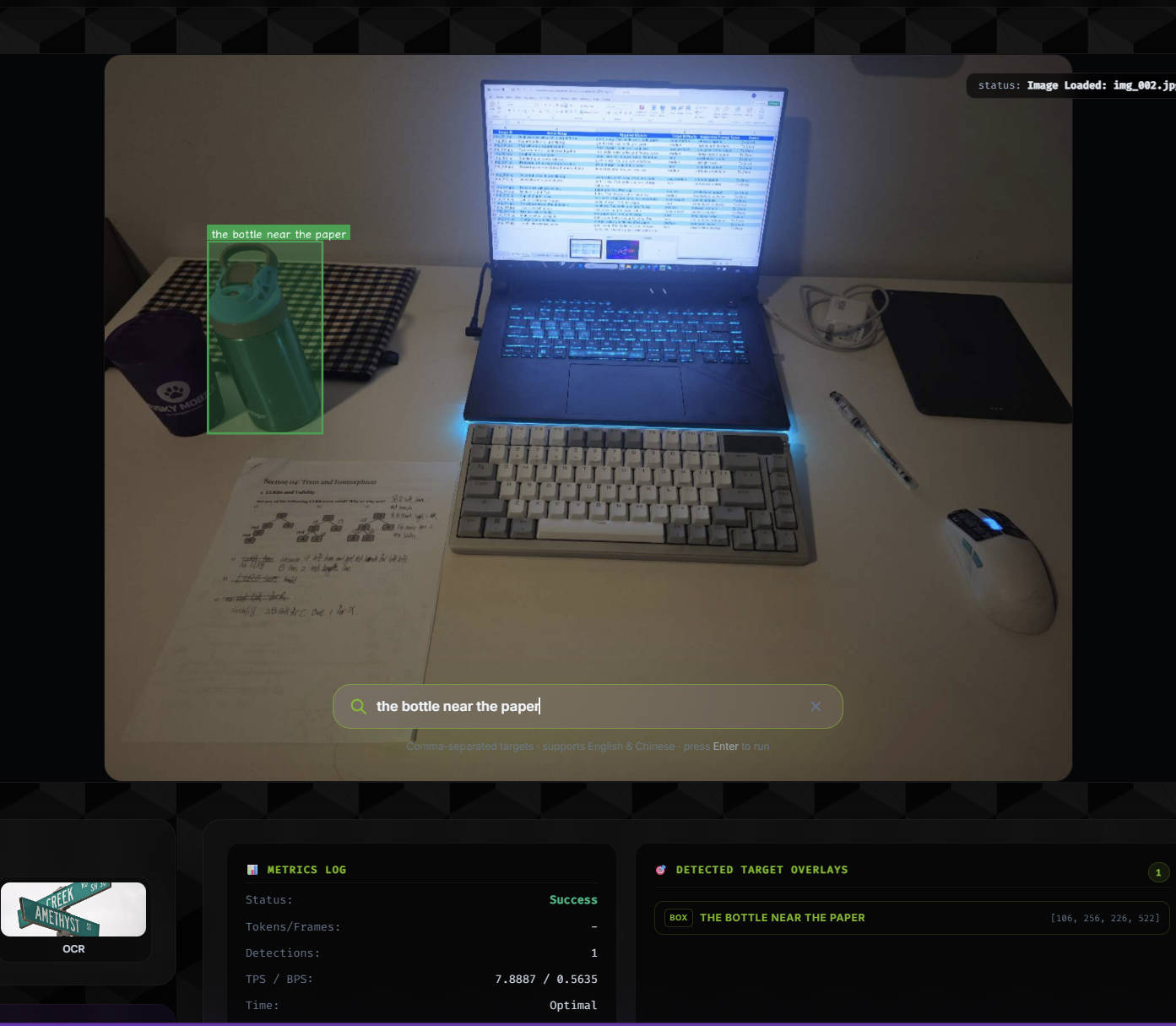
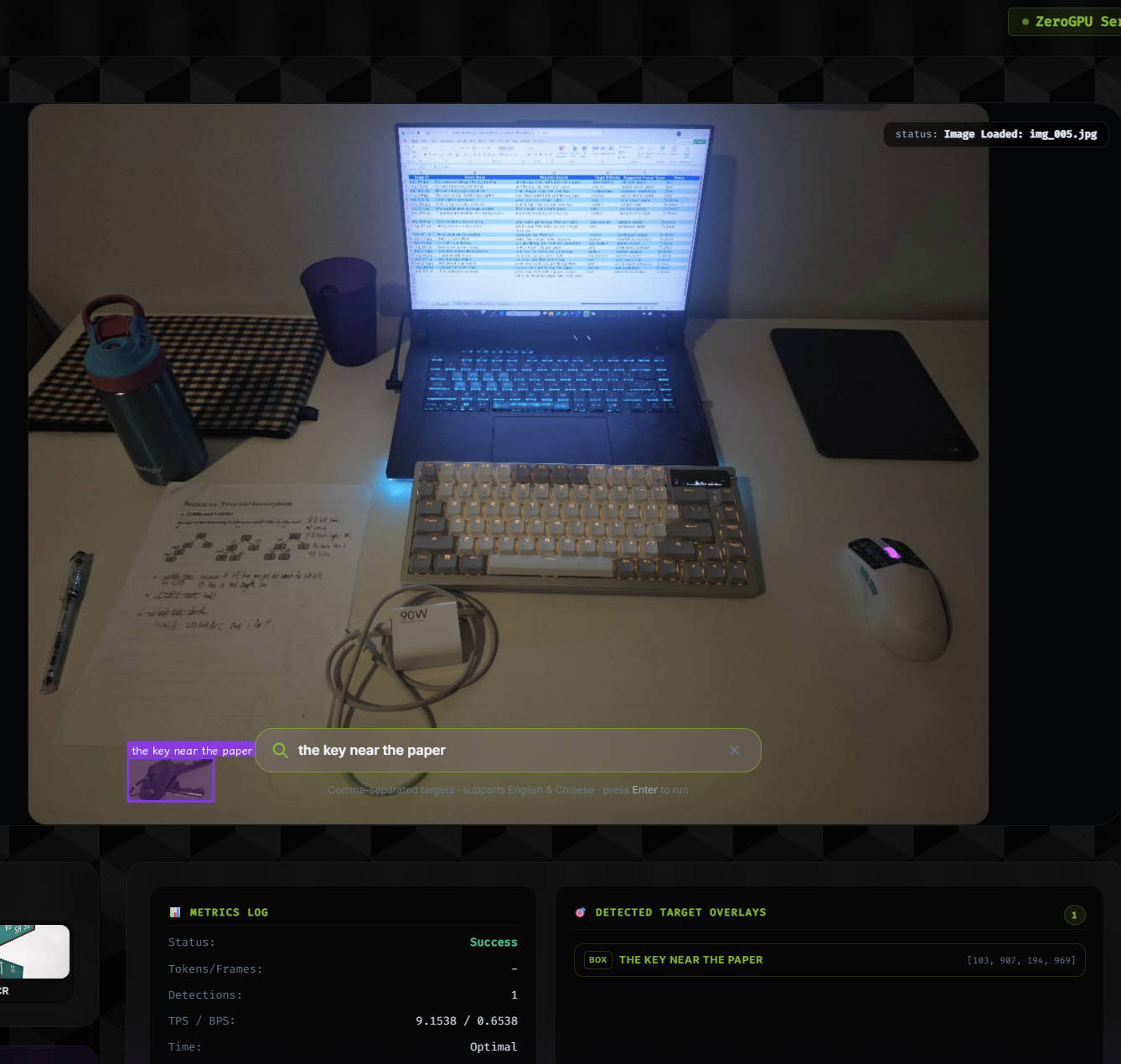
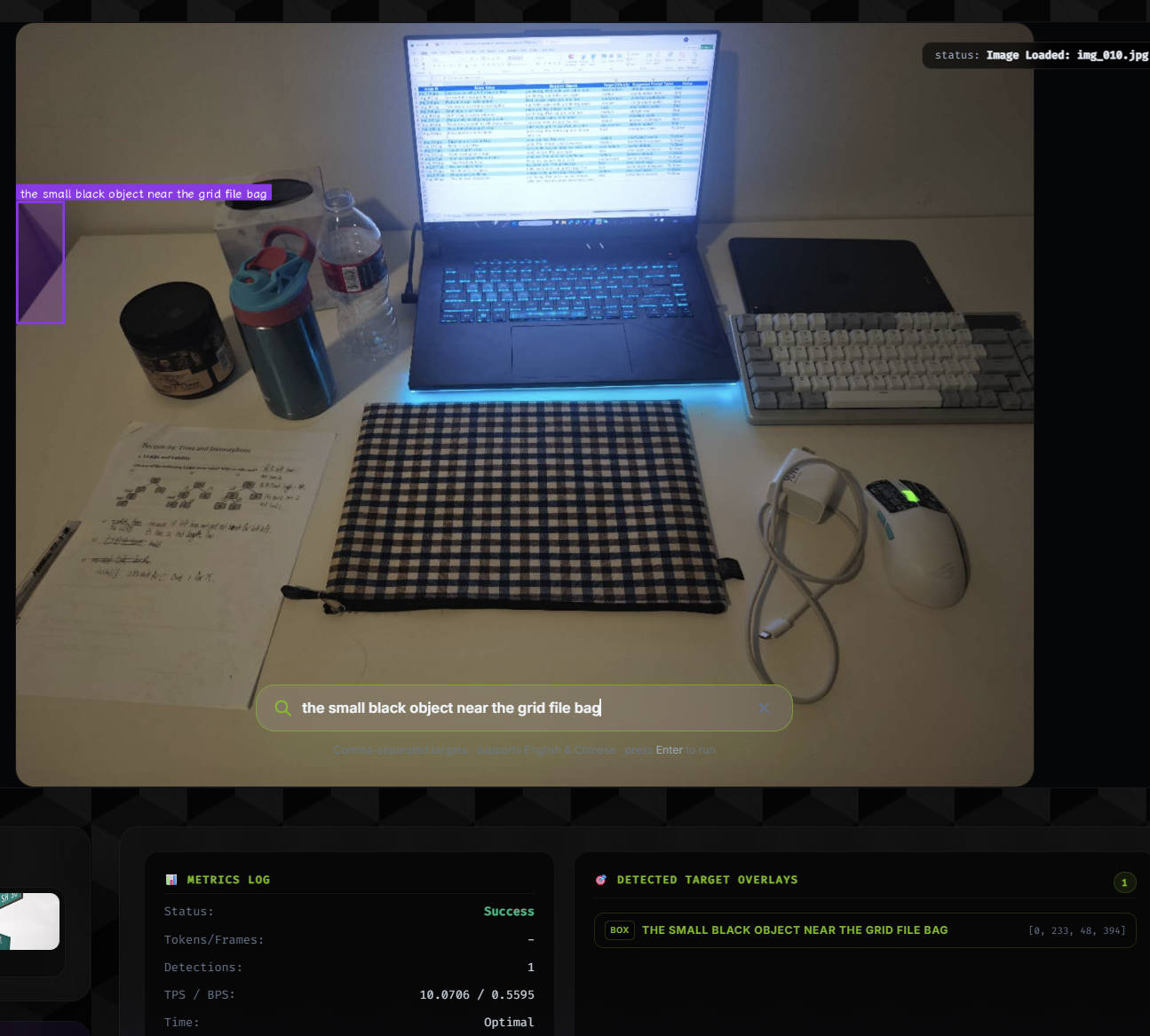
Evaluated LocateAnything on 39 valid tabletop image-prompt pairs for language-guided pre-grasp 2D object localization, achieving 0.646 mean IoU and 76.9% success at IoU >= 0.5.
Humanoid robots need perception modules that can interpret natural-language instructions such as object names, spatial relations, and task-relevant referring expressions.
Problem Definition
Determine whether LocateAnything can localize intended tabletop targets accurately enough to support the perception stage before grasp planning.
Technical Approach
Collected cluttered desk and tabletop scenes, wrote natural-language prompts, manually annotated ground-truth 2D boxes, and evaluated predictions with IoU, center-point error, success rate, and qualitative failure modes.
System Architecture / Design
An RGB image and text prompt are passed into LocateAnything. The predicted region is converted into a box or center point and compared against manual annotations.
Implementation Details
Built a 39-sample valid mini-pilot after excluding one no-target prompt. Prompt groups included spatial relation, similar object, small object, occlusion, and ambiguous prompt cases.
Challenges and Solutions
Small or thin target objects
Ambiguous referring expressions
Partial occlusion and spatial confusion
No reliable per-query timing from the web demo
Results / Outcome
39 valid image-prompt pairs
Mean IoU: 0.646
Median center-point error: 17.2 px
Overall success rate: 76.9% at IoU >= 0.5
Spatial-relation prompts: 93.8% success
Small-object prompts: 58.3% success
Ambiguous prompts: 33.3% success
Reflection
The project showed that open-vocabulary visual grounding can be useful for pre-grasp perception when the target is clearly described, but robust humanoid deployment would require depth sensing, segmentation, confidence estimation, clarification dialogue, and real robot validation.